Stack
Proof metrics
Evaluation scorecard
Production eval dimensions — how this system is judged before and after changes ship.
vs. baseline: Single-turn accuracy
Score agent changes on operational impact, not reply quality alone
Separation between agent execution, evaluation hooks, and policy iteration
Methodology applied before customer-facing agent changes reach production
Problem
Most agent demos optimize for demo-quality replies, not sustained reliability in production workflows.
Teams need structure for iterating prompts, tools, and policies when the scorecard is operational impact.
Solution
Worked with Hive's outcome-oriented abstractions to stress-test evaluation habits for agent systems.
Used the fork as a sandbox for methodology that complements production Claude agent work.
Technical deep-dive
Why outcome loops beat toy benchmarks
Most agent evals optimize for whether the model said something plausible in one turn. Production agents fail differently: they lose state, mis-route tools, or pass happy-path tests while breaking reconciliation under real data.
Hive's outcome-oriented abstractions force you to define what success means in business terms — fewer false positives, faster audit close, lower manual rework — and iterate against that scorecard.
How this complements WaybillAgent
WaybillAgent is the application proof; this fork is the eval discipline behind it. The same mindset — staged rollout, observable KPIs, verification before handoff — shows up in both the framework exploration and the production agent build.
Long-horizon failure modes
Agents fail mid-session: tool timeouts, partial writes, resumed state with stale context. Outcome evals force you to score recovery — not just the first successful tool call.
That is the bridge to MCP enterprise integration: tools must be idempotent, observable, and gated by the same business scorecard as the agent policy itself.
Architecture
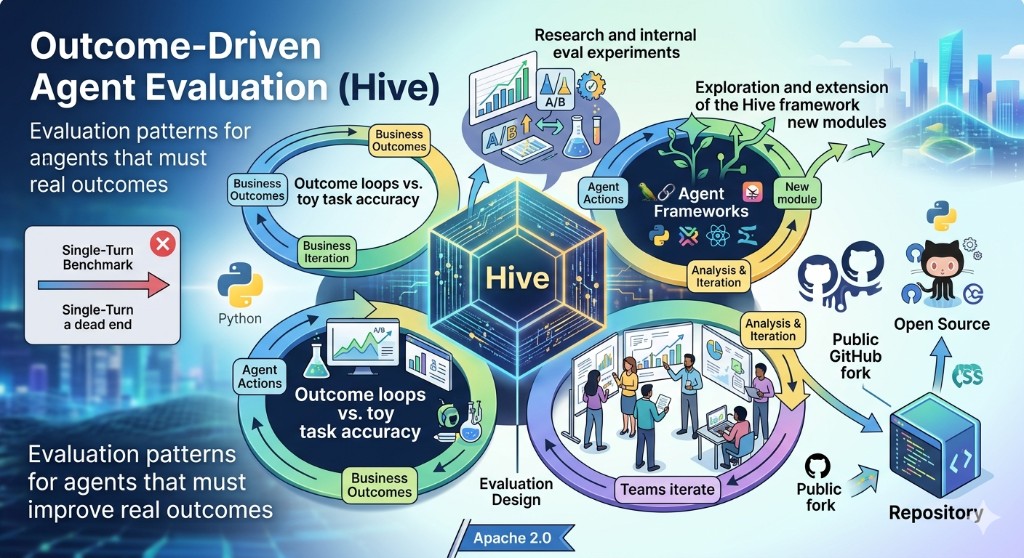
Python framework surfaces for defining agent behaviors and measurement hooks.
Separation between execution, evaluation, and iteration workflows.
Outcomes
Sharper internal discipline for judging agent changes before they reach customer-facing products.
Public footprint in the agent evaluation conversation beyond application code alone.
Links & artifacts
Related work
WaybillAgent
WaybillAgent transforms warehouse auditing from a multi-day manual process into an AI-assisted guided walk using phone capture and agentic reconciliation—flagship build for the Built with Opus 4.7 hackathon hosted by Cerebral Valley and Anthropic (selected top ~500 of 13,000+ applicants).
Read case studySoko ERP
Soko is a production multi-tenant ERP for East African SMBs — now live with 500+ businesses, 2.1M+ transactions, and 99.9% uptime. One platform for POS, multi-location inventory, HR/payroll, accounts, and reporting, with M-Pesa, offline-first sync, and multi-currency support (KES/UGX/TZS).
Read case studyDiscuss this work
Hiring or building something similar—reach out with context and constraints.
Email Joseph